




NaNa Lab
수 천 개의 텍스트 파일을 엑셀 하나로 합쳐 보자(1) 본문
본 강좌는 이전 강좌에서부터 이어지는 내용입니다. 파일 합치기는 이전 강좌에서 이미 다룬 내용이고 본 강좌에서는 csv형태로 파일을 저장하는 데 주안점을 둘 것이므로 굳이 이전 강좌를 읽고 오실 필요는 없습니다. 하지만 실습을 원하신다면 이전 강좌를 읽고 오셔야 실습에 사용할 더미 데이터를 생성하는 과정부터 따라 해 보실 수 있습니다.
수 천 개의 텍스트 파일을 1초 안에 합쳐 보자 (1)
이 매거진은 컴퓨터공학을 전공하지 않은 일반인들을 위한 업무 자동화 강좌입니다. 반드시 첫 화부터 순차적으로 글을 읽으실 필요는 없지만 파이썬 3 프로그래밍을 위한 개발 환경을 컴퓨터��
bhban.tistory.com
수 천 개의 텍스트 파일을 1초 안에 합쳐 보자 (2)
이 글은 이전 강좌에서 못다 한 과제를 마저 수행하기 위한 강좌입니다. 이전 강좌를 읽고 오시는 것을 추천합니다. https://bhban.tistory.com/48 자, 이제 personal_info 폴더 안에는 2천 개의 가짜 개인정��
bhban.tistory.com
본 강좌는 이전 강좌에서부터 이어지는 내용입니다. 파일 합치기는 이전 강좌에서 이미 다룬 내용이고 본 강좌에서는 csv형태로 파일을 저장하는 데 주안점을 둘 것이므로 굳이 이전 강좌를 읽고 오실 필요는 없습니다. 하지만 실습을 원하신다면 이전 강좌를 읽고 오셔야 실습에 사용할 더미 데이터를 생성하는 과정부터 따라 해 보실 수 있습니다.
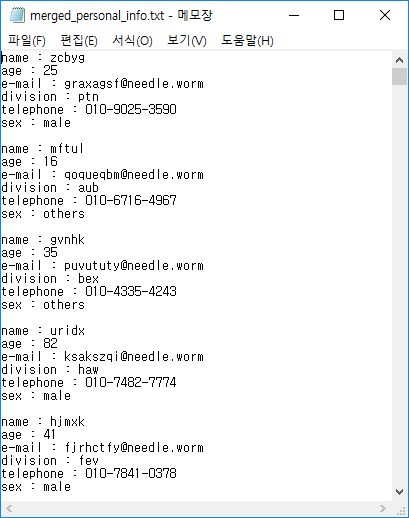
지난 시간에 만들었던 merged_personal_info.txt를 열어 보라. 수 천 개의 텍스트 파일을 하나로 합치는 것 까지는 좋았지만 모양이 왠지 예쁘지가 않다. 가독성이 낮아 보이지 않는가? 이왕 파이썬에게 하청을 줘서 합치는 거, 엑셀에 예쁘게 정리할 수 있으면 더욱 좋을 것이다.
오늘은 CSV형식으로 파일을 저장하는 방식을 다루어 볼 것이다. 일단 가장 간단한 방법은 그냥 open 함수에서 저장할 파일 이름을 수정하는 것이다. main.py를 열어 9번째 줄의 outfile_name을 수정해 보자. 맨 뒤의 파일 확장자를 txt가 아니라 csv로 바꾸면 된다. 그 후 코드를 저장하고, main.py를 실행해 보면 아래와 같은 결과물이 저장된다.

어째 엑셀 창이 뜨기는 뜨는데 예쁘지가 않다. 기존 작업물에 비해 전혀 가독성에 이점이 없는 것 같다. 어떻게 하면 예쁘게 저장할 수 있을까?
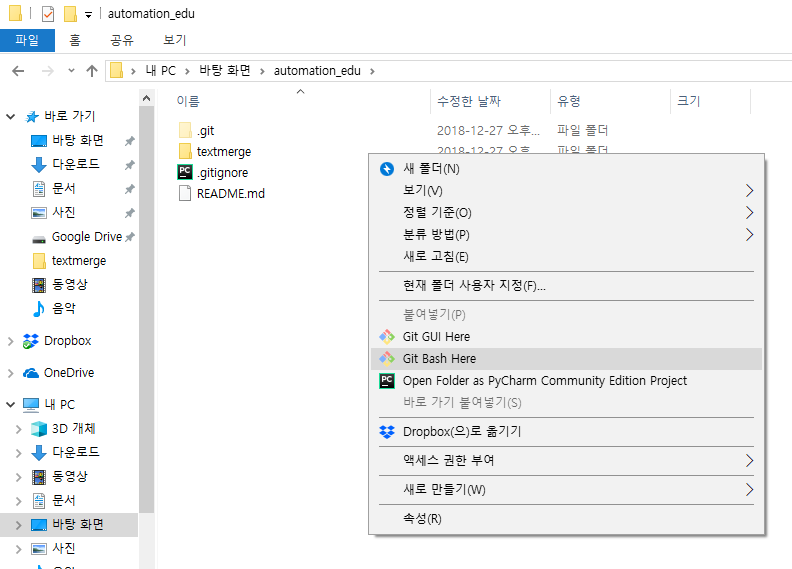
자, automation edu 폴더로 이동해 git bash를 켜 주자. 그리고 아래 명령어를 입력하자.
git remote -v

위와 같이 url이 정상적으로 뜨는지 확인하면 된다. 문제가 있다면 automation_edu 폴더를 삭제하고 레포지토리를 다시 clone 하자. clone 하는 방법은 이 글을 참고하자.
정상적인 상태라면 아래 명령어를 입력하자.
git pull origin master
그러면 필자가 새로이 업로드한 예제 코드들이 여러분의 컴퓨터로 자동으로 설치가 될 것이다. 위 명령어는 마스터 브랜치라는 곳에 있는 최신 내용을 가져와 여러분 컴퓨터의 오래된 버전의 코드를 최신으로 업그레이드해 주는 역할을 수행한다. 자세한 것은 구글에 "깃허브"라고 검색해 보자.
여기서 아래 명령어를 입력해 보자.
ls
폴더 내부의 내용물을 모두 보여준다. 하얀색 글자는 파일, 파란색 글자는 폴더를 의미한다. 이제 textmerge/ 폴더로 이동해 보겠다. 아래 명령어를 입력하자.
cd textmerge/
cd는 change directory의 약자인 것 같은데 무엇의 약자인지 아는 독자가 있다면 댓글로 알려주시기 바란다. 이런 줄임말을 하나하나 외워 두면 다른 개발자 앞에서 겉멋 부리는데 큰 도움이 된다. 다시 ls 명령어를 입력해 보자.
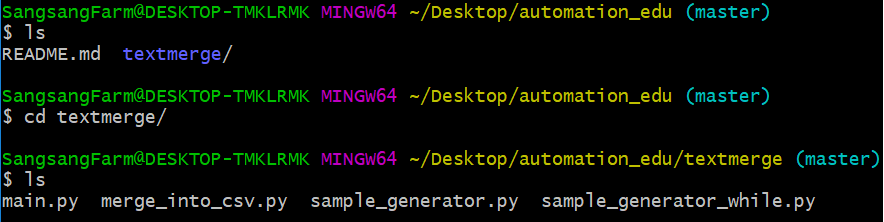
이번에는 textmerge폴더의 내용물이 보일 것이다. git bash를 껐다가 새로 켤 필요 없이, 동일한 창 안에서 다른 폴더로 이동할 수 있다. 상위 폴더로 이동하고 싶으면 아래 명령어를 입력하면 된다.
cd ..
앞으로는 여러분들이 git bash를 이용해 폴더를 이동하는 방법을 숙지하고 있다고 가정하고 설명을 할 것이다. 혹시 더 자세한 설명이 필요하다면 구글에 "리눅스 기본 명령어"라고 검색해 보자. 리눅스는 윈도나 맥 os 같은 컴퓨터 os의 일종이다. 여러분들 중 직장에서 업무를 자동화하는 것이 최종 목표인 사람은 아마 리눅스를 쓸 일이 앞으로도 없을 것이다. 하지만 혹시라도 관련 분야로 전공하거나 취직, 이직을 생각 중이라면 리눅스를 조금씩 공부해 두도록 하자.
자, ls를 한 결과물 중에 personal_info/ 폴더가 있는 사람도 있는 반면 그렇지 않은 사람도 있을 것이다. 스크린샷을 보면 필자의 경우 personal_info/ 디렉터리가 뜨지 않는다. 혹시나 디렉터리가 뜨지 않는다면 sample_generator_while.py를 실행해서 가짜 개인정보를 생성하자.
sample_generator_while.py는 기존의 sample_generator.py에서 발생한 몇 가지 문제를 수정한 것이다. 하지만 어떻게 수정했는지와 어떤 내용이 바뀐 것인지는 상세하게 설명하기가 너무나도 번거로우므로 여러분들이 직접 코드를 한 줄씩 비교해 보며 어떤 점이 달라졌는지 공부해 보기 바란다. 그러다 모르는 부분이 있으면 얼마든지 댓글로 질문을 남겨달라.
자, 그러면 이제 메인디쉬를 먹어보자. merge_into_csv.py를 실행하자.
python merge_into_csv.py
git bash의 작업이 끝났으면 ls를 입력해 보자.

merged_personal_info.csv라는 파일이 새로이 생겨 있다. 한번 더블클릭해 보자.

짜잔. 예쁘게 정리되었다.
CSV는 comma-separated values의 줄임말이다. 즉, 컴마로 구분된 값들이다. 한번 위 결과물을 메모장이나 파이참에서 읽어와 보자.

pycharm에서 불러온 결과물과 엑셀에서 실행한 모습의 차이를 살펴보자. 편의상 이를 텍스트 상태라고 부르겠다. 엑셀에서 좌우로 구분된 각각의 칸들은 택스트 상태에서 보면 컴마(,)로 구분되어 있다. 즉 컴마를 찍어서 데이터를 구분하고 .csv라는 확장자로 텍스트를 저장하면 우리가 아는 엑셀 모양으로 불러올 수 있게 되는 것이다. 엑셀에서 위아래로 구분된 각각의 행은 텍스트 상태에서도 다른 줄에 위치해 있다. 텍스트에서의 줄 바꿈(\n)은 엑셀에서도 줄 바꿈으로 표현되는 것이다.
앞으로 여러분들은 csv를 정말 많이 쓰게 될 것이다. 그러므로 csv형태에 대해서 반드시 이해하고 넘어갈 필요가 있다. 필자는 겉멋을 좋아하는 사람이다. 그런 사람이 반드시 필요하다고 강조하는 부분은 정말로 반드시 필요한 부분이다. 필자의 글만 읽어서 이해가 안 된다면 구글에 "csv 파일"이라고 검색해 보자.

저번 강좌의 main.py 코드와 크게 다른 점이 없으므로 설명은 생략한다. outfile_name의 확장자가 .csv로 바뀐 점 정도에만 주목하면 되겠다.
컴퓨터에게 어떤 작업을 시켰는지를 먼저 설명해 보도록 하겠다.
(1) 파일 이름을 목록에서 하나씩 차례대로 불러온다.
(2) 파일명에 ".txt"라는 문자가 없으면 (텍스트 파일이 아니면) 작업을 건너뛰고 for 루프의 다음 순서로 넘어간다.
(3) 파일을 하나씩 불러온다. 여기서 주의할 점은, 파일 하나가 사람 1명 분의 정보를 가지고 있다는 점이다.
(4) 지난 강좌에서 봤겠지만 컴퓨터는 파일을 위에서부터 한 줄씩 읽어온다.

위 개인정보를 위에서부터 한 줄씩 읽어온다고 생각해 보자. 읽어온 정보를 어떻게 가공하면 좋을까? 이렇게 생긴 수 천 개의 정보를 하나의 엑셀 파일로 합친다고 생각해 보자. ":"을 기준으로 왼쪽에 있는 문자는 우리 데이터의 헤더(header)에 해당한다. 헤더를 어떻게 번역할 수 있을까? 파일의 대가리 역할을 한다고 해서 헤더라고 부른다고 생각하면 된다. 항목? 범례? 여하튼 보통 엑셀에서 맨 윗줄에 적어두는, 카테고리 역할을 하는 그 값이다.
이제 여기서부터는 퍼즐게임이 된다. 흔히들 말하는 "알고리즘"이라는 것을 설계해야 문제를 풀 수 있다. 프로그래머에게 경험과 센스가 왜 중요한지를 조금씩 느껴보기 바란다.
필자는 아래와 같이 문제를 해결하려고 했다.
① 개인정보를 한 줄씩 불러온다. (그리고 이걸 line이라고 부른다.)
② ":"라는 글자를 기준으로 line을 둘로 쪼갠다. 그러면 첫 번째 줄을 기준으로 "name ", " ijfao\n" 두 개의 문자열로 쪼갤 수 있다. (우리 눈에 줄 바꿈으로 보이는 부분은 '\n'이라는 문자가 삽입되어 있다.
③ 두 개로 쪼개진 line의 좌측 부분은 모든 파일들이 공통으로 공유하는 양식이다. 이 데이터는 엑셀로 변환할 때 헤더 역할을 수행하도록 하면 될 것이다. line의 우측 부분은 각각의 사람들이 가진 고유한 특별한 값이다. 엑셀에서 한 칸씩 이 정보를 옆으로 나열하고, 사람이 바뀌면 엔터키를 한번 쳐 주는 식으로 데이터를 정리하면 될 것이다.
④ 수천 개의 파일을 순서대로 읽어와서 반복 작업을 수행할 것인데, 이 과정에서 line의 오른쪽 값은 반복해서 out_file에 적어준다.
⑤ 단, 첫 번째로 불러온 파일을 읽을 때에는 line의 좌측 값을 header로 설정해 준다. 이게 무슨 뜻이냐면, 파일이 2000개면 총 2000번 name, sex, age 등의 문자가 등장하는데 이걸 엑셀에도 2000번 반복해 적을 필요는 없으므로 한 번만 작업을 수행하자는 뜻이다. 엑셀에서는 name, age 등의 값은 맨 윗줄에만 적어 두면 충분하다.
이 중 가장 어려운 것은 5번이다. 지금부터 코드를 읽으며 설명을 할 것인데, 이해가 되지 않는다면 필자의 글이 아니라 코드를 읽으면서 여러 번 곱씹어 보기 바란다.
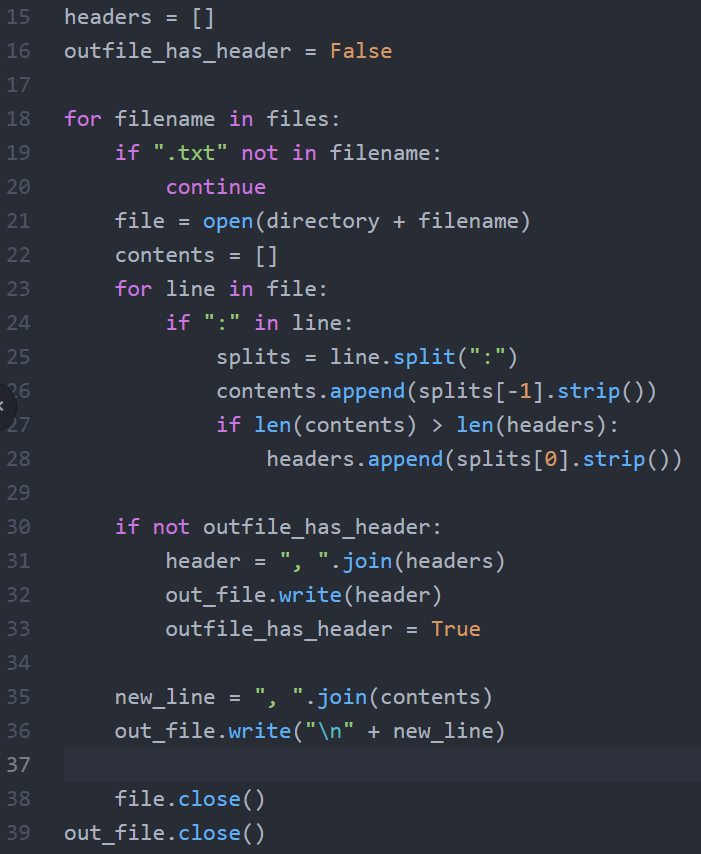
15번 줄에서는 header를 담아 줄 빈 리스트를 만들었다. 여러분은 이제 리스트가 무엇인지 잘 알 것이다. 모른다면 "파이썬 리스트"라고 구글에 검색해 보자.
16번 줄에서는 outfile_has_header라는 변수를 선언하고 이 변수의 값을 false라고 뒀다. false는 거짓이라는 뜻이다. 여러분은 "파이썬 조건문"을 이미 예습하고 왔을 것이므로 상세한 설명은 생략하도록 하겠다. 지금부터 이어질 코드에서는 outfile_has_header가 false이면 out_file에 header를 삽입한다. 만약 outfile_has_header가 True일 경우에는 out_file에 header를 삽입하지 않고 넘어갈 것이다. '혹시 이 작업이 이미 수행된 적이 있나요?'라는 질문에 대한 대답을 따로 적어두는 것이다.
18번 줄에서는 files의 내용물을 filename이라는 이름의 변수로 한 번에 하나씩 순서대로 불러와 반복문을 수행한다고 알리고 있다. 상세한 내용은 이전 강좌에서 설명했으므로 넘어간다.
19~20번 줄에서는 이름에 '.txt'라는 문자가 들어있지 않은 파일을 걸러내고 있다.
21번 줄에서는 파일을 실행하여 file이라는 이름의 변수로 초기화한다.
22번 줄에서는 각각 사람들의 개인정보를 저장할 텅 빈 리스트를 새로이 초기화하고 있다. contents라는 리스트는 새로운 파일을 불러올 때마다 매번 텅 빈 리스트로 정리된다.
23번 줄에서는 새로운 for문을 실행한다. 여기서는 file을 한 줄씩 차례대로 위에서부터 끝까지 불러오고, 마지막 줄을 불러온 뒤에는 작업을 종료할 것을 알리고 있다.
24번 줄에서는 조건문이 등장했다. line 내부에 ":"이라는 글자가 없으면 작업을 수행하지 않고 건너뛸 것이다.
25번 줄에서는 split() 함수가 등장한다. split() 함수는 string을 여러 개로 쪼개 주는 역할을 한다. 예를 들어서 다음과 같은 스트링이 있다고 치자.
"aaa, bbb, ccc, ddd, eee"
위 스트링에 split() 함수를 실행하면서 ","라는 인수를 제공하면 아래와 같은 결과가 나온다.

보시는 바와 같이 ','라는 글자를 발견하면 그걸 기준으로 이 문장을 쪼개버리는 것이다. 결과는 'aaa', ' bbb', ' ccc', ' ddd', ' eee' 라는 5개의 스트링이 담긴 리스트가 된다. 더 상세한 것은 구글에 "파이썬 split"이라고 검색해 보자.
25번 라인은 한 줄씩 불러온 데이터를 쪼개 준다. 두 개의 원소를 갖는 리스트가 되어 splits에 저장될 것이다. splits의 첫 번째 원소인 splits[0]은 header에 해당하고 splits[-1]은 content에 해당한다. 혹시 중괄호 안의 숫자가 이해가 안 된 다면 아직도 "파이썬 리스트"에 대해 검색을 해 보고 오지 않았다는 뜻이므로 서둘러 검색해 보고 오자.
26번 줄에서는 line의 우측 값에서 좌우 공백을 벗겨내는 strip 명령어를 실행했다. " aaa\n" 이라는 스트링에 strip 명령어를 실행하면 불필요한 좌우 공백과 이스케이프 문자를 벗겨내준다. 단어 뜻이 직관적이다. 왜, 옷을 벗고 춤추는 전문인력을 스트리퍼라고 부르지 않는가. 그 strip이랑 같은 단어다. 이스케이프 문자가 무엇인지 궁금하다면 구글에 "이스케이프 문자"라고 검색해 보기 바란다. 그렇게 벌거벗은 글자는 contents라는 리스트에 삽입된다. append는 리스트에 내용물을 삽입하는 연산인데, 이미 파이썬 리스트에 대해 검색하고 오셨을 테니 무슨 의미인지 잘 아실 거라 생각한다.
27번 줄에서는 contents 리스트와 headers 리스트의 길이를 비교한다. 여기서 '과연 이 파일이 첫 번째 순서로 불러온 파일인지 아닌지'가 구분된다. for loop가 처음 돌아 첫 번째 파일을 읽어 오고 있다면 아직 headers는 빈 리스트일 것이다. 순서상 한 줄씩 읽어온 데이터는 contents에 먼저 쌓이게 되므로 첫 번째 파일을 읽는 중에는 항상 contents의 길이가 headers의 길이보다 길어 저 조건문은 참이 되고, 두 번째 파일부터는 저 조건문은 항상 거짓이 된다. 조건문이 참일 경우, 그러니까 첫 번째 순서의 파일을 읽어 오는 동안에는 line의 왼쪽 부분을 strip 해 header에 넣어준다. 이번 코드의 핵심적인 부분이므로 이 부분은 여러 번 읽고 반드시 이해하고 넘어가기 바란다.
30번 줄에서는 "outfile에 헤더가 있는지" 여부를 검사한다. 즉, "outfile에 헤더를 삽입하는 작업을 이미 끝내 뒀나요?"라는 질문을 한다. 조건문이 참이 되면, 즉 outfile_has_header가 false이면 아래 headers리스트의 내용물들을 하나의 큰 문자열로 합치면서 outfile에 적어준다. 그리고 outfile_has_header의 값을 True로 바꾼다. "이 작업 이미 끝냈음" 하고 메모를 해 두는 것이다.
31번 줄과 35번 줄에서는 join()이라는 함수가 등장한다. 자세한 것은 구글에 "파이썬 join"이라고 검색해 보기 바란다. 31번 줄에서는 header 리스트 내의 내용물들 사이사이에 ", "라는 스트링을 삽입하면서 하나의 스트링으로 합쳤고, 35번 줄에서는 content 리스트 내의 내용물들 사이사이에 ", "라는 스트링을 삽입하면서 하나의 스트링으로 합쳤다. 여러 개의 스트링을 원소로 갖는 리스트의 내용물을 하나로 합쳐 주는 함수이며, 합치면서 사이사이에 일정한 값을 끼워 넣을 수도 있는 유용한 함수다.
36번 줄에서는 join을 통해 완성된 new line을 out_file에 적어준다.
38번 줄에서는 파일 하나를 다 읽을 때마다 그 파일을 종료해 줬다.
39번 줄에서는 out_file 작성이 끝났으므로 파일을 종료해 줬다.

지금까지는 파이썬이 낯설고 파이썬 자체가 어려웠을 것이지만 오늘 과제는 '컴퓨터에게 어떤 순서로 일을 시키면 좋을지 고민하는 과정' 자체가 어려웠다. 유식한 말로 표현하면 '알고리즘이 어려웠다.'라고 할 수 있다.
어떤 과정을 거치며 컴퓨터를 잘 부려먹을 수 있었는지 이해가 될 때까지 여러 번 읽어보길 바란다. 가능하다면 코드를 직접 읽어 보면서 컴퓨터가 어떤 순서로 작업을 수행했는지를 곱씹어 보도록 하자.
자, 오늘은 텍스트 파일을 합치면서 csv파일로 만들었다. 하지만 csv파일은 완벽한 엑셀 파일은 아니다.
다음 시간에는 csv파일이 아니라 엑셀 파일, 즉 .xlsx 형태로 파일을 저장하는 방법을 알아보도록 하겠다.
이번에도 겉멋은 부릴 필요가 없다. 여기까지 따라온 여러분은 겉멋뿐만이 아니라 그냥 멋있다.
치즈케익 스튜디오
아트워크 그룹 치즈케익 스튜디오
cheesecake.quv.kr
코딩하는 공익
하루 만에 3만여 명이 본 브런치 화제의 글 〈크롤러를 이용해 우체국 등기우편을 자동으로 정리해 보자〉의 주인공, ‘코딩하는 공익’ 반병현 작가의 첫 에세이. 단숨에 인기를 얻고 좋은 일��
book.naver.com
법대로 합시다
이 책은 실생활에 쓰이는 법학지식, 교양 수준의 법학지식, 법이 무엇인지 가볍게 접해 보고자 하는 사람들을 위한 교양서적의 성격을 띠고 있습니다. 경제적 풍요를 위해 재테크에 시간을 투자
book.naver.com
실전 민사소송법
이 책은 도서출판 해피로라를 통해 2017년 출간된 ‘실전 민사소송법’의 2판 격에 해당합니다. 2019년 연말까지의 최신판례가 업데이트되었습니다. 이 책은 변호사시험 또는 변리사시험을 준비��
book.naver.com
공학자의 지혜묵상
공학자가 지혜를 다루는 성경인 잠언과 전도서를 묵상한 글입니다. 논리와 지성이 신학을 만나 생기는 화학반응을 고스란히 녹여보았습니다.
www.bookk.co.kr
'일반인을 위한 업무자동화' 카테고리의 다른 글
| 아이돌 사진 수 천장을 한 번에 다운로드해 보자 (3) (3) | 2020.05.31 |
|---|---|
| 아이돌 사진 수 천장을 한 번에 다운로드해 보자 (2) (0) | 2020.05.31 |
| 아이돌 사진 수 천장을 한 번에 다운로드해 보자 (1) (0) | 2020.05.31 |
| 수 천 개의 텍스트 파일을 엑셀 하나로 합쳐 보자(2) (0) | 2020.05.31 |
| 수 천 개의 텍스트 파일을 1초 안에 합쳐 보자 (2) (1) | 2020.05.30 |
| 수 천 개의 텍스트 파일을 1초 안에 합쳐 보자 (1) (2) | 2020.05.30 |
| 업무 자동화를 위한 첫걸음 - 깃과 IDE 세팅 (1) | 2020.05.29 |
| 단순 업무는 컴퓨터에게 시키고 꿀을 빨아야 한다 (0) | 2020.05.29 |



